
O NTP
NTP significa Network Time Protocol ou Protocolo de Tempo para Redes. É o padrão que permite a sincronização dos relógios dos dispositivos de uma rede como servidores, estações de trabalho, roteadores e outros equipamentos à partir de referências de tempo confiáveis. Além do protocolo de comunicação em si, o NTP define uma série de algoritmos utilizados para consultar os servidores, calcular a diferença de tempo e estimar um erro, escolher as melhores referências e ajustar o relógio local.
OBS: ao longo desta página utiliza-se o comando ntpq da distribuição do NTPsec para exemplificar o acesso às variaveis do sistema ligadas a cada conceito. O Chrony e outras implementações completas do NTP usam internamente as mesmas variáveis e conceitos, definidas na especificação do NTP, mas as ferramentas de consulta, nomes e forma com que são apresentadas podem ser diferentes.
- Arquitetura do NTP
- O Funcionamento do NTP
- Troca de Mensagens e Cálculo do Deslocamento
- O Algorítmo de Filtro de Relógio
- O Algorítimo de Seleção dos Relógios
- O Algorítmo de Agrupamento
- O Algorítmo de Combinação de Relógios
- Disciplina do Relógio Local
- NTS e Segurança
Arquitetura do NTP
Os servidores NTP formam uma topologia hierárquica, dividida em camadas ou estratos (em inglês: strata) numerados de 0 (zero) a 16 (dezesseis). O estrato 0 (stratum 0) na verdade não faz parte da rede de servidores NTP, mas representa a referência primária de tempo, que é geralmente um receptor do Sistema de Posicionamento Global (GPS) ou um relógio atômico. O estrato 16 indica que um determinado servidor está inoperante.
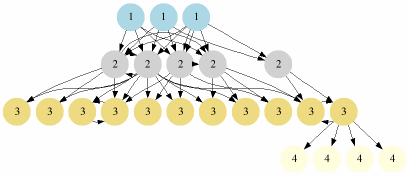
O estrato 0, ou relógio de referência, fornece o tempo correto para o estrato 1, que por sua vez fornece o tempo para o estrato 2 e assim por diante. O NTP é então, simultaneamente, servidor (fornece o tempo) e cliente (consulta o tempo). A topologia está ilustrada na Figura 1.
Em teoria, quanto mais perto da raiz, ou seja, do estrato 0, maior a exatidão do tempo. O estrato ao qual o servidor pertence é a principal métrica utilizada pelo NTP para escolher dentre vários, qual o melhor servidor para fornecer o tempo. Na prática, contudo, as diferenças de exatidão entre os estratos não são expressivas e há, no momento de escolher-se um conjunto de servidores de tempo para configurar um determinado cliente, outros fatores mais importantes a se considerar, como por exemplo a capacidade e carga à qual os servidores estão submetidos, o atraso e a assimetria da rede.
O estrato de um servidor não é uma característica estática. Se houver perda de conexão com as fontes de tempo, ou outros fatores que modifiquem a topologia da rede, o estrato pode variar.
Ao consultar-se a lista de servidores de referência no daemon NTP, o estrato (st) é informado:
# ntpq -p
remote refid st t when poll reach delay offset jitter
=======================================================================================================
+a.st1.ntp.br .ONBR. 1 8 17 64 377 1.2987 -0.6453 0.9893
-b.st1.ntp.br .ONBR. 1 8 12 64 377 15.6381 -0.5638 0.7459
c.st1.ntp.br 200.160.7.186 2 3 352 64 40 9.5079 -2.3322 0.0000
+d.st1.ntp.br .ONBR. 1 8 10 64 37 9.5089 -0.7145 3.8351
*gps.jd.ntp.br .GPS. 1 8 7 64 377 1.2081 -0.4014 0.8255
-time.cloudflare.com 10.106.8.9 3 8 2 64 377 115.6774 -0.2651 1.9029
-ntsts.sth.ntp.se 194.58.202.20 2 8 7 64 377 195.3313 -0.8140 0.7210
As relações entre os diferentes dispositivos NTP são normalmente chamadas de Associações. Elas podem ser:
- Permanentes: são criadas por uma configuração ou comando e mantidas sempre. Este é o tipo de associação recomendável para se trabalhar em aplicações do dia a dia.
- Priorizáveis (preemptables): são específicas da versão 4 do NTP e criadas por uma configuração ou comando, podem ser desfeitas no caso de haver um servidor melhor, ou depois de um certo tempo.
- Efêmeras ou transitórias: são criadas por solicitação de outro dispositivo NTP e podem ser desfeitas em caso de erro ou depois de um certo tempo.
São possíveis as seguintes Associações:
-
Cliente/servidor: (client - server) É uma assiciação permanente e a forma mais comum de configuração. Um dispositivo faz o papel de cliente, solicitando informações sobre o tempo a um servidor. O cliente tem conhecimento das associações com os servidores e do estado da troca de pacotes. Outro dispositivo faz o papel de servidor, respondendo à solicitação do cliente com informações sobre o tempo. O servidor não armazena informações sobre o diálogo com o cliente ou sobre sua associação com o mesmo.
No processo, então, o cliente envia um pacote ao servidor a aguarda a resposta, que vem em seguida. Isso pode ser descrito também como uma operação do tipo pull, dizendo que o cliente busca os dados necessários sobre o tempo no servidor.
Para configurar o cliente dessa forma é usado o parâmetro
serverno arquivo de configuração, seguido do nome ou endereço do servidor. É recomendável também usar adicionalmente o parâmetroiburstno comando, que serve para acelerar a sincronização inicial.Um cliente pode criar associações com vários servidores simultaneamente. Na verdade é recomendável que seja assim. E um servidor pode fornecer tempo a diversos clientes simultaneamente.
Pela forma com que o protocolo foi projetado, um dispositivo (host) NTP pode ser cliente e servidor ao mesmo tempo. Alguns softwares, como o NTPSec e a implementação de referência do NTP, que hoje é considerada legada, não permitem a separação das funções, ou seja, sempre abrem sockets e atuam como servidores, mesmo que o usuário só precise deles como clientes. Isso pode ter implicações de segurança e muitas vezes é necessário o uso de firewalls. O Chrony consegue operar apenas como cliente, se corretamente configurado. O OpenNTPD e o systemd-timesyncd foram desenhados para operar apenas como clientes.
O modo cliente/servidor é o modo recomendado pelo NTP.br para a operação do NTP. É o único modo que opera com NTPsec. Apenas use outros modos se tiver uma necessidade específica e souber com muita certeza o que está fazendo.
-
Modo simétrico: (symmetric mode) Apenas a Dois ou mais dispositivos NTP podem ser configurados como pares (peers), de forma que possam tanto buscar o tempo, quanto fornecê-lo, garantindo redundância mútua. Essa configuração faz sentido para dispositivos no mesmo estrato, configurados também como clientes de um ou mais servidores. Caso um dos pares perca a referência de seus servidores, os demais pares podem funcionar como referência de tempo.
O modo simétrico pode ser:
-
Ativo: O dispositivo A configura o dispositivo B como seu par (criando dessa forma uma associação permanente). Por sua vez, o dispositivo B também configura o dispositivo A como seu par (também cria uma associação permanente).
-
Passivo: O dispositivo A configura o dispositivo B como seu par (modo simétrico ativo). Mas o dispositivo B não tem o dispositivo A na sua lista de servidores ou pares. Ainda assim, ao receber um pacote de A, o dispositivo B cria uma associação transitória, de forma a poder fornecer ou receber o tempo de A.
Esse modo é particularmente susceptível a ataques, onde um dispositivo intruso pode estar configurado no modo simétrico ativo e fornecer informações de tempo falsas para outro. Por isso deve sempre ser usado com criptografia.
Para configurar um dispositivo no modo simétrico utiliza-se o parâmetro
peer, seguido do nome ou IP do par. Com o modo simétrico não deve-se utilizar os parâmetrosburstouiburst.Para evitar a falha de segurança descrita no modo simétrico passivo, caso opte por utilizá-lo, ignorando as recomendações contra isso deste site, deve-se sempre manter a autenticação habilitada. Isso é o padrão do sistema. Para desabilitar a autenticação inclui-se o parâmetro
disable authno arquivo de configuração. Não desabilite a autenticação, a menos que se entenda muito bem as conseqüências e haja uma razão muito forte.Nota: no NTPSec esse modo não existe. Os parâmetros de configuração citados aqui são referentes à implementação de referência (legada) do NTP.
Note que no modo Cliente - Servidor não há nenhuma problema em configurar A como servidor de B e, ao mesmo tempo B como servidor de A.
-
-
Broadcast ou Multicast: O NTP pode fazer uso de pacotes do tipo broadcast ou multicast para enviar ou receber informações de tempo. Esse tipo de configuração pode ser vantajosa no caso de redes locais com poucos servidores alimentando uma grande quantidade de clientes.
O cliente NTP no modo broadcast ou multicast (à partir da versão 4), ao receber o primeiro pacote de um servidor, busca os dados por um curto período de tempo, como se estivesse no modo cliente - servidor, a fim de conhecer o atraso envolvido. Ou seja, durante alguns instantes há troca de pacotes entre cliente e servidor, depois disso o cliente passa apenas a receber os pacotes broadcast ou multicast do servidor.
Para configurar um servidor utiliza-se o parâmetro
broadcast, seguido do endereço IP de broadcast da interface de rede, ou de um endereço multicast. O IANA reservou os endereços multicast 224.0.1.1 (IPv4) e ff05::101 (IPv6 - site local) para o NTP, mas outros endereços podem ser utilizados. O parâmetrominpollcontrola o tempo entre pacotes e o parâmetrottlo número de saltos máximo de cada um deles.Para configurar o cliente utiliza-se o parâmetro
broadcastclient. Na versão 3 do NTP era necessário também utilizar o parâmetrobroadcastdelaypara definir o atraso de rede envolvido.Como no caso do modo simétrico passivo, há aqui uma questão de segurança, porque um intruso pode facilmente enviar pacotes NTP falsos em modo broadcast ou multicast. Então, caso opte por utilizar um desses modos, ignorando as recomendações contra isso deste site, mantenha sempre a autenticação habilitada. Isso é o padrão do sistema. Para desabilitar a autenticação inclui-se o parâmetro
disable authno arquivo de configuração. Caso opte por usar o modo broadcast ou multicast, não desabilite a autentiação, a menos que se entenda muito bem as conseqüências e haja uma razão muito forte.Nota: no NTPSec esse modo não existe. Os parâmetros de configuração citados aqui são referentes à implementação de referência (legada) do NTP.
Ao consultar-se a lista de servidores no NTP, o tipo de comunicação de dados na rede (t) é informado. Pode ser local, unicast, multicast ou broadcast. No exemplo a seguir todos os servidores usam unicast. Valores numéricos indicam o uso de NTS, que só é possível em associações do tipo cliente/servidor, que são unicast. Se não houver uso de NTPSec o unicast é representado pela letra u:
# ntpq -p
remote refid st t when poll reach delay offset jitter
=======================================================================================================
+a.st1.ntp.br .ONBR. 1 8 13 128 377 1.3328 0.0157 0.2488
-b.st1.ntp.br .ONBR. 1 8 122 128 377 14.8119 -0.2101 0.2674
-c.st1.ntp.br 200.160.7.186 2 5 398 128 210 9.5676 0.1762 0.1518
+d.st1.ntp.br .ONBR. 1 8 64 128 377 9.6119 0.0372 0.0709
*gps.jd.ntp.br .GPS. 1 8 46 128 377 1.3747 0.0688 0.2298
-time.cloudflare.com 10.106.8.9 3 8 38 128 377 115.6220 -0.6353 0.1363
-ntsts.sth.ntp.se 194.58.202.20 2 8 11 128 377 195.3852 -0.0832 0.1344
O Funcionamento do NTP
Como já visto, NTP é um protocolo de rede que permite a sincronização dos relógios dos dispositivos à partir de referências de tempo confiáveis. Num primeiro momento isso pode parecer algo tão simples quanto "consultar o tempo em um servidor" e "ajustar o relógio local" de tempos em tempos. Na verdade, algumas implementações do SNTP, a versão simplificada do protocolo, fazem isso e apenas isso. Mas o NTP em sua forma completa é muito mais complexo.
Diversos componentes do sistema colaboram para:
- Obter, à partir de diversas amostras, informações de tempo de um determinado servidor, como o deslocamento, dispersão e variação.
- Discernir, dentre um conjunto de servidores, quais fornecem o tempo correto e quais estão mentindo.
- Escolher, dentre os servidores que fornecem o tempo correto, qual é a melhor referência.
- Disciplinar o relógio local, descobrindo seus principais parâmetros de funcionamento, como precisão, estabilidade e escorregamento e ajustando-o de forma contínua e gradual, mesmo na ausência temporária de referências de tempo confiáveis, para que tenha e melhor exatidão possível.
- Garantir a monotonicidade do tempo.
- Identificar, à partir de métodos criptográficos, servidores de tempo conhecidos e confiáveis, evitando possíveis ataques.
- Formar, em conjunto com outros servidores NTP, uma topologia simples, confiável, robusta e escalável para a sincronização de tempo.
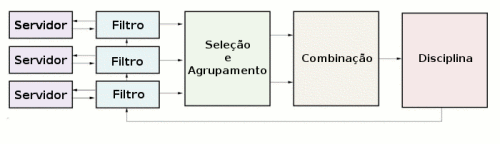
A Figura 2 mostra os principais componentes do NTP, que são apresentados e explicados de uma forma bastante simplificada no texto a seguir. Para informações mais precisas sobre como são calculadas as várias métricas do sistema e sobre como devem funcionar os diversos algorítmos, recomenda-se a consulta direta às RFCs e à documentação oficial.
Troca de Mensagens e Cálculo do Deslocamento
As mensagens do NTP são baseadas no protocolo UDP, que é um protocolo não confiável e não orientado à conexão.
A troca de mensagens entre cliente e servidor permite que o cliente descubra qual seu deslocamento (offset) em relação ao servidor, ou seja, o quanto seu relógio local difere do relógio do servidor.
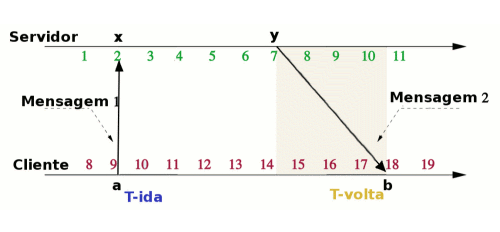
Consideremos servidor e cliente com relógios não sincronizados. A troca de mensagens, ilustrada na Figura 3, dá-se da seguinte forma:
- O Cliente lê seu relógio, que fornece o tempo a.
- O Cliente envia a Mensagem 1 com a informação de tempo a para o servidor.
- O Servidor recebe a Mensagem 1 e nesse instante lê seu relógio, que fornece o instante x. O Servidor mantém a e x em variáveis.
- O Servidor após algum tempo lê novamente seu relógio, que fornece o instante y.
- O Servidor envia a Mensagem 2 com a, x e y para o cliente.
- O Cliente recebe a Mensagem 2 e nesse instante lê seu relógio, que fornece o instante b.
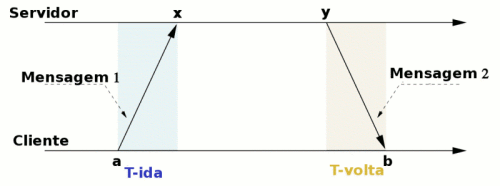
Ao receber a Mensagem 2, o Cliente passa a conhecer os instantes a, x, y e b. Mas a e b estão numa escala de tempo, enquanto x e y em outra. O valor do incremento dessas escalas é o mesmo, mas os relógios não estão sincronizados.
Não é possível, então, calcular o tempo que a Mensagem 1 levou para ser transmitida (T-ida), nem o tempo que a Mensagem 2 gastou na rede (T-volta). Contudo, o tempo total de ida e volta, ou atraso (também conhecido por Round Trip Time ou RTT) que é a soma T-ida + T-volta pode ser calculado como:
atraso (delay) = (b-a)-(y-x).
Considerando-se que o tempo de ida é igual ao tempo de volta, pode-se calcular o deslocamento entre o servidor e o relógio local como como:
deslocamento (offset) = x - (a + atraso/2) =
deslocamento (offset) = (x-a+y-b)/2.
Para facilitar a compreensão, considere-se o seguinte exemplo numérico.
- O Cliente lê o relógio: a=9.
- O Cliente envia a Mensagem 1 (a=9).
- O Servidor recebe a Mensagem 1 (a=9) e lê seu relógio: x=4.
- O Servidor algum tempo depois lê seu relógio novamente: y=9.
- O Servidor envia a Mensagem 2 (a=9, x=4, y=9).
- O Cliente recebe a Mensagem 2 (a=9, x=4, y=9) e lê seu relógio: b=18.
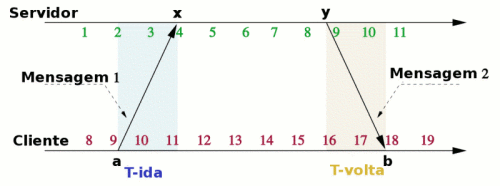
Ao olhar a Figura 4, é fácil observar que T-ida=2 e T-volta=2. Contudo, nem o Cliente nem o Servidor têm essa visão. O Servidor ao final da troca de mensagens descarta todas as informações sobre a mesma. O Cliente conhece as variáveis a=9, x=4, y=9 e b=18, mas à partir delas é impossível calcular T-ida ou T-volta. Contudo, é possível calcular o atraso e o deslocamento:
atraso = (b-a)-(y-x) = (18 - 9) - (9 - 4) = 9 - 5 = 4
deslocamento = (x-a+y-b)/2 = (4-9+9-18)/2 = -14/2 = -7
Um deslocamento de -7 significa que o relógio local do Cliente deve ser atrasado 7 unidades de tempo para se igualar ao do Servidor.
Note-se que foi assumido alguns parágrafos acima, para se conseguir calcular o deslocamento, que T-ida = T-volta. Mas isso nem sempre é verdade! Há atrasos estocásticos nas redes devido às filas dos roteadores e switchs. Numa WAN ou na Internet enlaces de diferentes velocidades e roteamento assimétrico, além de outros fatores, também causam diferenças entre T-ida e T-volta.
No entanto o NTP funciona exatamente dessa forma, considerando que T-ida = T-volta.
Isso implica num erro. Esse erro, representado na Figura 5, é no pior caso igual à metade do atraso. Ou seja:
deslocamento - atraso/2 <= deslocamento verdadeiro <= deslocamento + atraso/2

Tome-se o seguinte exemplo numérico, ilustrando o pior caso. Os servidores são os mesmos da Figura 4, mas a primeira mensagem leva um tempo desprezível pra ser enviada, enquanto a segunda demora 4 unidades de tempo: a=9; x=2; y=7; b=18. Nesse caso T-ida=0 e T-volta=4. O exemplo está ilustrado na Figura 6.
Calcula-se o atraso como:
atraso = (b-a)-(y-x) = (18 - 9) - (7 - 2) = 9 - 5 = 4.
deslocamento = (x-a+y-b)/2 = (2-9+7-18)/2 = -18/2 = -9.
O deslocamento está errado! Sabe-se que o valor correto é -7, contudo o valor calculado é -9. Isso deve-se a assimetria da rede, no tocante a T-ida e T-volta.
No entanto, à partir do cálculo do deslocamento e do atraso, e levando em conta a limitação do método, que considera T-ida=T-volta, sabe-se que o deslocamente verdadeiro está entre:
deslocamento - 2 <= deslocamento verdadeiro <= deslocamento + 2
-9 -2 <= deslocamento verdadeiro <= -9 + 2
-11 <= deslocamento verdadeiro <= -7
Ou seja, dado um deslocamento de -9 e um atraso de 4, sabe-se que o valor verdadeiro do deslocamento é algo entre -11 e -7, mas não há como ter certeza de qual o valor. Como nesse exemplo o valor correto é conhecido de antemão, -7, pode-se verificar que o cálculo funciona adequadamente.
O Algorítmo de Filtro de Relógio
Através da troca de mensagens, o NTP consegue as informações de atraso e deslocamento de um servidor. Essa troca de mensagens não é realizada uma única vez. Ela se repete periodicamente, com o período dinamicamente controlado pelo NTP.
No início da sincronização o cliente NTP faz uma consulta a cada servidor a cada 64s. Esse período varia ao longo do tempo, geralmente aumenta, até chegar a 1024s (aproximadamente 17min). As variáveis minpoll e maxpoll definem o mínimo e o máximo, e são representadas em potência de 2. Ou seja, por padrão minpoll = 6 (26=64) e maxpoll = 10 (210=1024).
Numa consulta à lista de servidores NTP, a variável poll representa o período e a variável when é um contador que indica quantos segundos se passaram desde a última consulta; quando poll = when uma nova consulta é realizada e a variável when é zerada (se a consulta é bem sucedida). Se o parâmetro iburst é utilizado na configuração de um servidor, a taxa de envio de pacotes é acelerada no início da sincronização, de forma a se conseguir um conjunto de dados mais depressa.
A variável reach representa um registrador de deslocamento de 8 bits, cujo valor é mostrado no formato octal. Um bit 1 significa que o cliente obteve resposta do servidor para uma consulta. Então o valor 377 = 11.111.111, significa que as últimas 8 consultas ao servidor foram bem sucedidas. Valores diferentes de 377 mostram que algumas consultas falharam, dando indícios de problemas de conectividade ou com o servidor em questão.
# ntpq -p
remote refid st t when poll reach delay offset jitter
=======================================================================================================
+a.st1.ntp.br .ONBR. 1 8 31 256 377 1.3075 0.0494 0.0653
-b.st1.ntp.br .ONBR. 1 8 253 256 377 15.6301 0.0736 0.0916
-c.st1.ntp.br 200.160.7.186 2 7 278 256 42 9.5679 -0.0234 0.1970
+d.st1.ntp.br .ONBR. 1 8 233 256 377 9.5892 -0.0286 0.0334
*gps.jd.ntp.br .GPS. 1 8 71 256 377 1.2993 -0.0204 0.0810
-time.cloudflare.com 10.106.8.9 3 8 55 256 377 115.6377 -0.6794 0.2105
-ntsts.sth.ntp.se 194.58.202.20 2 8 18 256 377 195.4044 -0.1319 0.1477
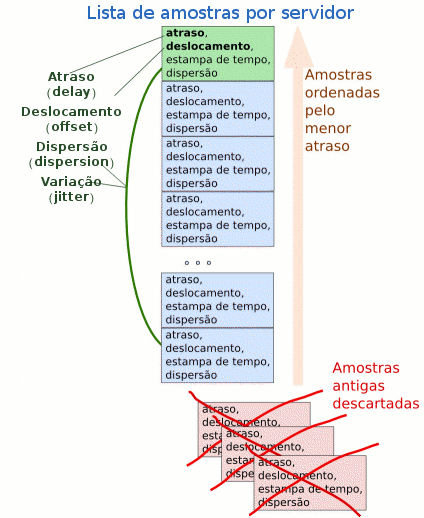
É importante notar então, que não há apenas um valor de atraso e um de deslocamento para cada servidor, mas um conjunto deles, provenientes das diversas trocas de mensagem! A partir dessa lista de valores, o Algorítmo de Filtro de Relógio calcula então um valor de atraso (delay), de deslocamento (offset) e de variação (jitter).
Na verdade, cada amostra é composta de 4 valores: atraso, deslocamento, dispersão e estampa de tempo. A estampa de tempo indica quando a amostra chegou. A dispersão é o erro estimado do relógio de servidor remoto, informada pelo servidor na mensagem NTP.
A lista com os valores é ordenada em função do atraso. Considera-se que as amostras com menor atraso são melhores porque provavelmente não se sujeitaram a filas nos switches e roteadores, de forma que parte das variações estocásticas de tempo no envio e recebimento das mensagens é evitada com essa escolha.
Os valores mais antigos são descartados, porque o valor de deslocamento pode não mais corresponder à realidade, já que a exatidão do relógio local varia ao longo do tempo.
Após descartar as amostras antigas, resta uma lista com as amostras mais recentes e ordenadas em função do atraso. Da primeira entrada dessa lista são retiradas as variáveis atraso e deslocamento para o par cliente servidor (note-se que para cada par cliente - servidor há uma variável de cada tipo).
A dispersão e a variação são calculadas levando em conta todos os valores da lista.
A Figura 7 ilustra o funcionamento desse algorítmo.
Os valores para cada servidor associado podem ser consultados no NTP conforme o exemplo a seguir, que detalha os valores para o primeiro servidor da lista:
# ntpq
ntpq> pe
remote refid st t when poll reach delay offset jitter
=======================================================================================================
+a.st1.ntp.br .ONBR. 1 8 57 256 377 1.3075 0.0494 0.0813
-b.st1.ntp.br .ONBR. 1 8 24 256 377 15.6619 0.1686 0.1017
-c.st1.ntp.br 200.160.7.186 2 5 826 256 210 9.5679 -0.0234 0.1970
+d.st1.ntp.br .ONBR. 1 8 244 256 377 9.5892 -0.0286 0.0252
*gps.jd.ntp.br .GPS. 1 8 89 256 377 1.2993 -0.0204 0.0699
-time.cloudflare.com 10.106.8.9 3 8 77 256 377 115.6447 -0.5374 0.1880
-sth-ts.nts.netnod.se 194.58.202.20 2 8 25 256 377 195.3548 -0.1202 0.1407
ntpq> rv &1
status=f43a conf, authenb, auth, reach, sel_candidate, 3 events, sys_peer,
srcadr=2001:12ff:0:7::186, srcport=123, dstadr=2804:xxxx::xxxx:xxxx:xxxx:xxxx, dstport=123, leap=00, hmode=3, stratum=1, ppoll=99, hpoll=8, precision=-22,
rootdelay=0.0, rootdisp=1.175, refid=ONBR, reftime=e591ae1f.4c38b98d 2022-01-18T21:22:39.297Z, rec=e591ae2b.f170a70f 2022-01-18T21:22:51.943Z,
xmt=e591ae2b.f146b66c 2022-01-18T21:22:51.942Z, reach=377, unreach=0, delay=1.307455, offset=0.049402, jitter=0.081301, dispersion=13.356646, keyid=0,
filtdelay =1.34 1.72 1.44 1.31 1.45 1.70 1.34 1.47, filtoffset =0.03 0.21 0.08 0.05 0.07 0.17 0.01 -0.00, pmode=4,
filtdisp =0.00 3.98 7.83 11.72 15.77 19.79 23.66 27.71, flash=00 ok, headway=2, srchost="a.st1.ntp.br", ntscookies=8
O Algorítimo de Seleção dos Relógios
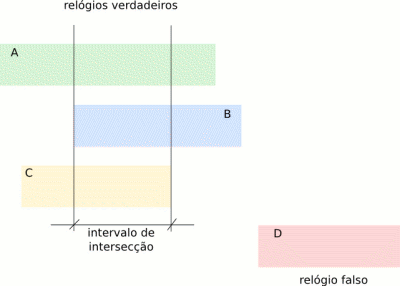
Uma vez que o Algorítmo de Filtro de Relógios tenha calculado os principais parâmetros referentes a cada servidor, faz-se importante descobrir quais deles são confiáveis e quais não. Os servidores que têm algum erro no tempo fornecido são chamados de relógios falsos (falsetickers, na literatura em inglês, a tradução é aproximada). Os servidores que fornecem a hora corretamente são chamados de relógios verdadeiros (truechimmers, em inglês, uma tradução mais literal seria algo como "badaladores verdadeiros").
Para a seleção dos relógios, o NTP considera como verdadeiro o deslocamento que se encontra dentro de um determinado intervalo de confiança, representado na Figura 8. Esse intervalo é calculado, para cada associação com um servidor, como:
intervalo de confiança = (deslocamento/2) + dispersão.

A Seleção de relógios busca um intervalo de intersecção para os valores de deslocamento de cada servidor, considerados os intervalos de confiança. Os servidores cujos deslocamentos ficam fora da intersecção são relógios falsos. A Figura 9 ilustra isso para 4 servidores, A, B e C são relógios verdadeiros, e D é um relógio falso:
Ao consultar-se a lista de servidores do NTP, os relógios falsos são identificados por um "x". No exemplo abaixo, o servidor6 é um relógio falso (esses símbolos, como o "x", usados para diferenciar os servidores, são chamados de tally-codes, para mais detalhes deve-se consultar a seção Configurações Avançadas.):
usuario@cliente.local:~$ ntpq -p remote refid st t when poll reach delay offset jitter ====================================================================== -servidor1 .IRIG. 1 u 8 32 377 0.407 0.248 0.016 -servidor2 .GPS. 1 u - 32 377 0.474 0.213 0.019 +servidor3 .GPS. 1 u 9 64 377 15.680 -0.005 0.026 +servidor4 .IRIG. 1 u 30 64 377 15.582 0.004 0.100 *servidor5 .GPS. 1 u 10 32 377 0.400 -0.026 0.049 xservidor6 .IRIG. 1 u 26 64 377 7.824 9.923 0.367 -servidor7 .ACTS. 1 u 13 64 377 202.274 2.459 0.309
O Algorítmo de Agrupamento
O algorítmo de Agrupamento trabalha com os servidores que são relógios verdadeiros, utilizando técnicas estatísticas, com o objetivo de selecionar os melhores dentre eles. Os critérios de seleção utilizados são:
- estrato (stratum)
- distância para a raiz
- variação (jitter)
No processo alguns servidores são descartados, sendo chamados de relógios afastados (outlyers). Os que permanecem são chamados de relógios sobreviventes (survivors), algumas vezes na literatura em inglês utiliza-se candidatos (candidates) no mesmo sentido que sobreviventes, por conta do algorítmo utilizado onde, à princípio, todos os relógios verdadeiros são candidatos, mas apenas alguns sobrevivem.
O melhor dos relógios sobreviventes é considerado como par do sistema (system peer).
Na consulta abaixo, o par do sistema é indicado pelo "*" (em verde); os relógios sobreviventes por "+" (em azul); e os relógios afastados por "-" (em laranja) (esses símbolos, como o "*", "+" e "-", usados para diferenciar os servidores, são chamados de tally-codes, para mais detalhes deve-se consultar a seção Configurações Avançadas.):
usuario@cliente.local:~$ ntpq -p remote refid st t when poll reach delay offset jitter ====================================================================== -servidor1 .IRIG. 1 u 8 32 377 0.407 0.248 0.016 -servidor2 .GPS. 1 u - 32 377 0.474 0.213 0.019 +servidor3 .GPS. 1 u 9 64 377 15.680 -0.005 0.026 +servidor4 .IRIG. 1 u 30 64 377 15.582 0.004 0.100 *servidor5 .GPS. 1 u 10 32 377 0.400 -0.026 0.049 xservidor6 .IRIG. 1 u 26 64 377 7.824 9.923 0.367 -servidor7 .ACTS. 1 u 13 64 377 202.274 2.459 0.309
O Algorítmo de Combinação de Relógios
Se o algorítmo de Agrupamento encontrar apenas um sobrevivente, ele será o par do sistema e será utilizado como referência para ajustar o relógio local. Se for usada a palavra chave prefer na configuração de um servidor e este estiver dentre os sobreviventes, ele será considerado como par do sistema e, mesmo que existam outros sobreviventes, estes serão ignorados. Nesses casos, o algorítmo de Combinação de Relógios não é utilizado.
Para os demais casos, quando há mais do que um sobrevivente e nenhum deles foi configurado com a palavra chave prefer, o algorítmo de Combinação de Relógios calcula uma média ponderada dos deslocamentos dos relógios, com o objetivo de aumentar a exatidão.
No exemplo abaixo os 3 servidores destacados contribuem para o valor de deslocamento de 0,025ms, mostrado nas variáveis do sistema.
usuario@cliente.local:~$ ntpq
ntpq> pe
remote refid st t when poll reach delay offset jitter
=======================================================================================================
+a.st1.ntp.br .ONBR. 1 8 93 256 377 1.3075 0.0494 0.0772
-b.st1.ntp.br .ONBR. 1 8 72 256 377 15.6619 0.1686 0.1283
-c.st1.ntp.br 200.160.7.186 2 5 874 256 210 9.4701 -0.0379 0.1623
+d.st1.ntp.br .ONBR. 1 8 25 256 377 9.6502 -0.0446 0.1964
*gps.jd.ntp.br .GPS. 1 8 137 256 377 1.3452 0.0307 0.1123
-time.cloudflare.com 10.106.8.9 3 8 124 256 377 115.6751 -0.4607 0.2155
-sth-ts.nts.netnod.se 194.58.202.20 2 8 72 256 377 195.3548 -0.1202 0.1274
ntpq> rl
associd=0 status=0015 leap_none, sync_unspec, 1 event, clock_sync,
leap=00, stratum=2, precision=-23, rootdelay=1.345, rootdisp=29.464, refid=66.125.246.65, reftime=e591af12.f1832fb2 2022-01-18T21:26:42.943Z, tc=8,
peer=17771, offset=0.025247, frequency=-0.205963, sys_jitter=0.082688, clk_jitter=1.020751, clock=e591b2b6.14232158 2022-01-18T21:42:14.078Z,
processor="x86_64", system="Linux/5.10.0-10-amd64", version="ntpd ntpsec-1.2.0 2021-06-17T05:15:04Z", clk_wander=0.062884, tai=37, leapsec="2017-01-01",
expire="2022-06-28T", mintc=0
No exemplo a seguir, apesar de haver 3 sobreviventes, foi usada a palavra chave prefer na configuração do a.st1.ntp.br. Como ele é um dos sobreviventes, foi escolhido como par do sistema e é o único responsável pelos parâmetros de sincronização. Nesse caso, o algorítmo de Combinação de Relógios não é utilizado:
usuario@cliente.local:~$ ntpq
ntpq> pe
remote refid st t when poll reach delay offset jitter
=======================================================================================================
*a.st1.ntp.br .ONBR. 1 8 37 64 377 1.2229 0.0686 0.0360
-b.st1.ntp.br .ONBR. 1 8 36 64 377 16.4064 -0.2762 0.0480
c.st1.ntp.br 200.160.7.186 2 6 182 64 104 9.2609 0.0977 0.1038
+d.st1.ntp.br .ONBR. 1 8 26 64 377 9.5379 -0.0023 0.0474
+gps.jd.ntp.br .GPS. 1 8 37 64 377 1.3029 0.0351 0.0678
-time.cloudflare.com 10.106.8.9 3 8 32 64 377 115.4933 -0.4144 0.0892
-sth-ts.nts.netnod.se 194.58.202.20 2 8 35 64 377 195.3971 -0.0725 0.1032
ntpq> rl
associd=0 status=0015 leap_none, sync_unspec, 1 event, clock_sync,
leap=00, stratum=2, precision=-24, rootdelay=1.223, rootdisp=3.962, refid=76.127.35.142, reftime=e591b624.870a4f00 2022-01-18T21:56:52.527Z, tc=6,
peer=17767, offset=0.068553, frequency=-0.265198, sys_jitter=0.036016, clk_jitter=0.035563, clock=e591b64c.a514292c 2022-01-18T21:57:32.644Z,
processor="x86_64", system="Linux/5.10.0-10-amd64", version="ntpd ntpsec-1.2.0 2021-06-17T05:15:04Z", clk_wander=0.007326, tai=37, leapsec="2017-01-01",
expire="2022-06-28T", mintc=0
Disciplina do Relógio Local
O processo de disciplina do Relógio Local controla a fase e a freqüência do relógio do sistema. Ele é baseado na combinação de duas filosofias de controle bastante diferentes entre si: Phase Locked Loop (PLL) e Frequency Locked Loop (FLL) (traduções desses termos são incomuns, mas poderiam ser Laço Controlado por Fase e Laço Controlado por Freqüência). Ambas as filosofias implementam controles onde há realimentação, ou seja, onde a informação de saída é usada novamente na entrada, como simbolizado na Figura 2, no início desse texto (e repetida a seguir).
O controle baseado em fase é melhor para as ocasiões onde há uma grande variação (jitter). Essa abordagem procura minimizar o erro no tempo, controlando indiretamente a freqüência.
O controle baseado em freqüência é melhor para quando há instabilidades na freqüência (variações mais lentas que o jitter, conhecidas como wander). A abordagem controla diretamente a freqüência, e indiretamente o erro no tempo.
O NTP disciplina o relógio local de forma contínua, mesmo em períodos onde não é possível consultar servidores de tempo. As características do relógio local são medidas e se tornam conhecidas do NTP, o que torna possível que ele funcione dessa forma. O arquivo indicado pela chave driftfile (geralmente /var/lib/ntpsec/ntp.drift) na configuração armazena o erro esperado de freqüência para o relógio.
Algumas características importantes desse algorítmo:
-
Saltos no tempo são evitados sempre que possível. O tempo é ajustado para mais ou para menos gradualmente, variando-se a freqüência do relógio local.
-
Se uma diferença maior do que 128ms for detectada o NTP considera que o tempo está muito errado, e que é necessário um salto para frente ou para trás para corrigi-lo. Contudo isso só é feito se essa diferença maior que 128ms persistir por um período maior que 900s (15min), para evitar que condições de congestionamento grave mas temporário na rede, que podem levar a medições erradas de tempo, causem inadvertidamente esse tipo de salto.
Se uma diferença maior que 1000s (~16,7min) for detectada o algorítmo aborta a execução, considerando que algo muito errado aconteceu. Se houver diferenças dessa ordem ou maiores elas devem ser corrigidas manualmente antes de se executar o daemon NTP.
NTS e Segurança
Por segurança no contexto da Tecnologia da Informação entende-se basicamente garantir quatro propriedades da informação:
- integridade,
- disponibilidade,
- autenticidade e
- confidencialidade.
Os algorítmos vistos anteriormente, aliados à correta configuração do sistema, com um número suficiente de fontes de tempo com referências primárias independentes, garantem de forma satisfatória a integridade e disponibilidade do serviço de tempo.
Os algorítimos de criptografia abordados neste item visam garantir a autenticidade da informação. Ou seja, têm o objetivo de assegurar ao cliente de que o servidor é quem ele diz ser.
A confidencialidade não é considerada um problema no contexto do NTP. Ou seja, a informação de tempo sempre trafega na rede de forma aberta, sem criptografia, mesmo quando uma assinatura cifrada é utilizada para garantir a autenticidade da informação. As razões principais para o NTP funcionar dessa forma são que:
- o tempo é uma informação pública, não há razão para esconder essa informação;
- trabalhar com a informação de tempo cifrada demandaria tempo tanto do servidor quando do cliente e degradaria o desempenho do sistema, fazendo-o menos exato.
Foram especificados 3 métodos no NTP para realizar a autenticação, chave simétrica (symmetric key) e chave pública com (autokey) e NTS, que também usa chave pública.
Autenticação por Chave Simétrica
A autenticação por chave simétrica é o esquema utilizado originalmente na versão 3 do NTP, mas mantido da versão 4. Um conjunto de chaves deve ser gerado e compartilhado entre servidor e cliente. O NTP não fornece meios para a transmissão ou armazenamento seguro das chaves; isso deve ser feito com outros recursos.
Chaves simétricas podem ser usadas para:
- autenticar servidores no modo cliente/servidor;
- autenticar pares no modo simétrico ativo ou passivo;
- autenticar servidores no modo broadcast ou multicast;
- autenticar requisições dos programas de monitoração e controle, como
ntpq.
Quando o daemon NTP é iniciado, ele lê o arquivo de chaves especificado pelo comando keys no arquivo de configuração e armazena-as num cache. Cada chave deve ser ativada com o comando trustedkey antes de ser usada. Isso pode ser feito também com o programa em funcionamento, utilizando o ntpq (na implementação legada de referência isso era feito pelo comando ntpdc que não existe mais no ntpsec).
O arquivo de chaves pode conter várias chaves, uma em cada linha. Cada linha tem 3 colunas. A primeira é o número da chave, entre 1 e 65535. A segunda é o tipo da chave; recomenda-se utilizar M para MD5, que é representada por uma seqüência de até 31 caracteres ASCII (A versão 3 do NTP suportava também DES, mas além de ser pior, há problemas legais nos Estados Unidos, que consideram programas utilizando DES como munição, proibindo sua exportação). A terceira é a chave em si. Exemplo de arquivo com chaves:
1 M ABCDEFGHIJLMJNOPQRST 2 M ESSAEHUMACHAVEMD5VALIDA 3 M ESSAEHUMACHAVEMD5VALIDATB 15 M 1234ACDAS@#$LKAS)KJDKASH 498 M NTPv4.98
Exemplo de utilização das chaves simétricas na configuração do ntp:
server servidor1.dominio1 key 498 server servidor2.dominio2 key 2 server servidor3.dominio3 key 3 # caminho para o arquivo com as chaves keys /etc/ntpsec/ntp.keys # define quais chaves são confiáveis trustedkey 2 15 498
A autenticação por chave simétrica funciona bem, é suportada por uma grande variedade de dispositivos, mesmo antigos, e pode ser usada. O grande problema é que ela não traz consigo uma forma para distribuição das chaves. Ou seja, servidor e cliente devem ter configurada e confiar na mesma chave. Ela precisa estar configurada tanto no servidor, como no cliente.
Essa distribuição deve ser feita de forma segura, garantindo que não haja erros ou vazamento da informação, sob pena de toda a segurança extra provida pelo recurso ser perdida. Normalmente isso é feito de forma manual. O NIST, por exemplo, que é uma das instituições responsáveis por manter os padrões de tempo e frequência nos Estados Unidos, suporta as chaves simétricas em seu serviço de NTP: eles recebem as requisições por correio (correio, físico, cartas em papel) ou fax e enviam a chave simétrica a ser utilizada também por carta.
Autenticação por Chave Pública com Autokey
Na versão 4 do NTP uma nova forma de autenticação foi criada, baseada em chaves públicas e num protocolo que foi chamado de autokey. A integridade dos pacotes seria verificada através de chaves MD5 e a autenticidade das fontes de tempo averiguada por meio de assinaturas digitais e vários esquemas de autenticação. Esquemas de identificação (identity schemes) baseados em trocas do tipo desafio/resposta seriam usados para evitar vários tipos de ataques aos quais o método de chaves simétricas poderia ser potencialmente vulnerável.
O Autokey foi um fracasso completo. Ele está documentado na RFC 5906, que é uma RFC informational, ou seja, não especifica realmente um padrão. Hoje o Autokey é considerado obsoleto. Não deve ser usado. Os softwares modernos para NTP não o suportam mais. Esse fracasso se deu por inúmeras falhas de segurança em sua concepção e implementação, restrições como não funcionar com NAT, bem como por causa da enorme dificuldade de configuração e uso.
NTS - Network Time Security
A segurança não era uma preocupação para a maior parte da comunidade técnica que procurava sincronizar os relógios dos seus dispositivos no passado. Mas recentemente muita coisa mudou:
- a Internet cresceu e se descentralizou;
- há muitas evidências de um tratamento inadequado da segurança no NTP, por exemplo o uso em larga escala do NTP em ataques DDoS de reflexão e o enorme número de falhas de segurança encontradas na implementação de referência, que é um verdadeiro dinossauro, gigante, e com suporte a uma miríade de hardwares e sistemas obsoletos e cujas opções padrão de configuração não são seguras;
- há uma interdependência crescente entre o registro do tempo, a manutenção correta do tempo e a segurança, por exemplo, considerando a necessidade dos logs com informação de data/hora corretas para o tratamento de incidentes, ou a dependência de algorítmos de criptografia e mecanismos de login do relógio correto;
- há hoje requisitos legais e de conformidade que exigem ou dependem da manutenção e registro corretos do tempo nos sistemas;
Ataques bem sucedidos ao NTP podem ser catastróficos, afetando uma infinidade de sistemas. Por exemplo, se um ataque NTP conseguir fazer um cliente voltar no tempo, ele pode aceitar certificados TLS fraudados. Certificados TLS são usados para estabeler conexões que deveriam ser seguras e autenticadas na Internet, mas houve já falhas de segurança que permitiram a emissão de certificados falsos no passado, como o heartbleed. Em relação ao DNSSEC, se um resolver estiver configurado para fazer strict validation um ataque NTP que leve o relógio para o futuro pode fazer com que todos os certificados e chaves expirem. Um ataque que leve para o passado pode facilitar ataques de repetição. Muitos sistemas hoje usam algum tipo de cache, o próprio DNS, por exemplo. Um ataque NTP que leve o relógio para trás apenas 24h pode fazer com que as entradas de cache expirem, inundando a rede de novas requisições. Um ataque NTP poderia afetar o RPKI e a segurança do BGP, por exemplo levando um validador para frente no tempo e fazendo com que apague o arquivo de manifesto e depois fazendo-o voltar e aceitando um manifesto antigo como válido. No Bitcoin um ataque NTP pode levar uma vítima a rejeitar transações válidas, ou a gastar poder computacional processando transações antigas. Há inúmeros exemplos da gravidade dos riscos de ataques bem sucedidos aos relógios dos sistemas. Essa deveria ser uma motivação muito séria para todos.
Um grupo de trabalho foi criado em 2015, no IETF, para tratar a situação, tendo concluído o trabalho de padronização de uma nova extensão de segurança para o NTP em setembro de 2020. Ela se chama NTS , sigla para Network Time Security.
O NTS é um mecanismo para usar TLS para prover segurança criptográfica para o NTP no modo cliente/servidor. TLS é o mesmo mecanismo de segurança, baseado em chaves públicas, amplamente utilizado na web, para garantir a autenticidade dos sites usando o protoco https. Confiável e amplamente conhecido e utilizado pela comunidade técnica.
O NTS tem dois componentes:
- NTS-KE - Network time Security Key Establishment: Um mecanismo que permite a autenticação do servidor pelo cliente e a troca de parâmetros de segurança que serão usados depois efetivamente na troca de informações NTP;
- NTS Extension fields for NTPv4: extensão do protocolo NTP que permite a autenticação dos pacotes e outros tipos de proteção;
O NTS provê, por meio do NTS-KE e das extensões NTS para o NTPv4:
- Identidade: usa a estrutura de chaves públicas X.509, já amplamente utilizada na web;
- Autenticação: verifica criptograficamente que a informação de relógio nos pacotes NTP é autêntica, produzida por um servidor identificável;
- Proteção contra ataques de repetição: o cliente pode detectar ataques de repetição;
- Consistência entre requisições e respostas: o cliente pode verificar que cada resposta do servidor corresponde a uma consulta feita anteriormente;
- Privacidade: NTS não vaza nenhuma informação que permitiria a um terceiro determinar que dois pacotes vindos de redes diferentes se originaram no mesmo cliente;
- Não amplificação: as respostas nunca são maiores do que as requisições;
- Escalabilidade: os servidores não guardam estado dos clientes, então podem servir a um grande número deles;
- Desempenho: o NTS não degrada a qualidade da sincronização dos relógios, ou seja, não piora a precisão/exatidão do NTP;
O funcionamento do NTS está ilustrado na figura 10, a seguir:
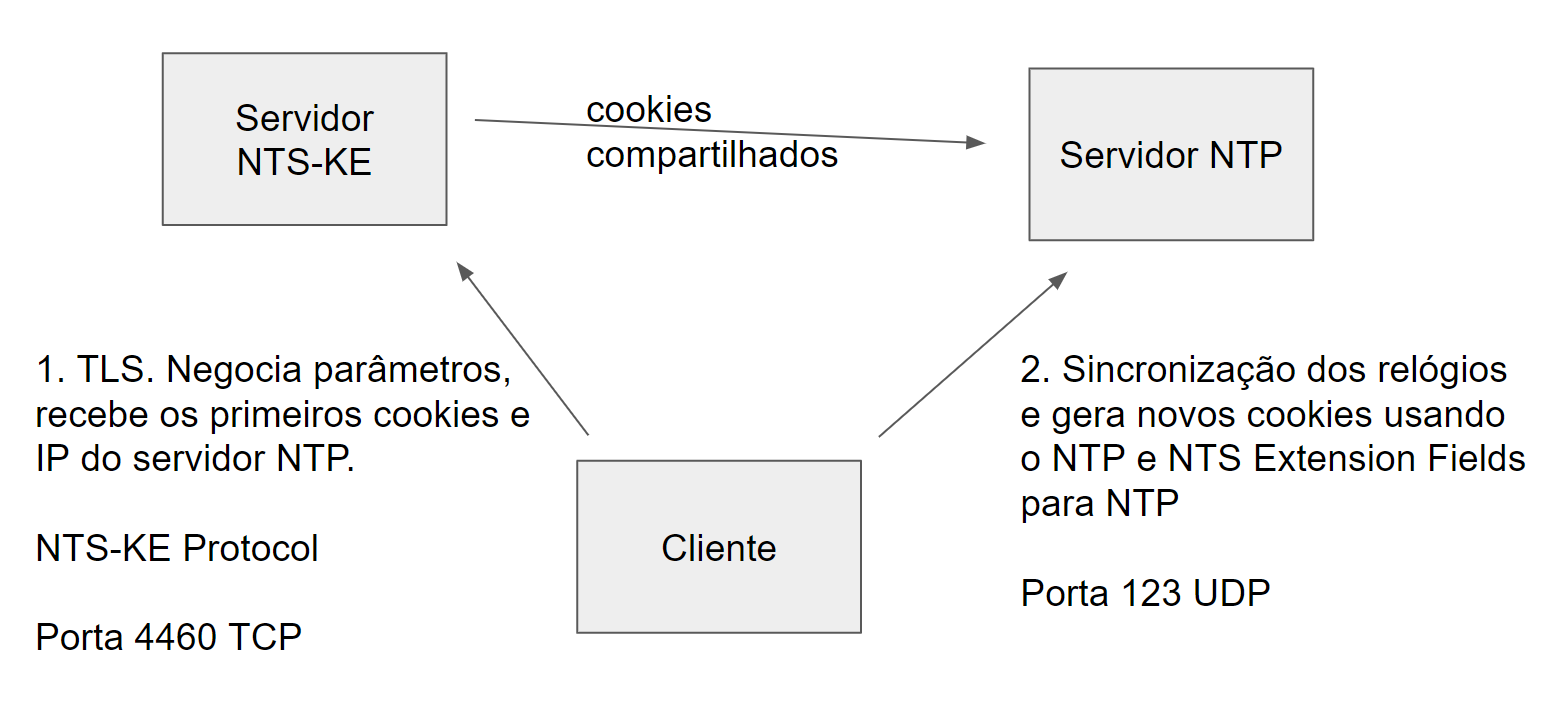
O primeiro passo é o NTS-KE: o cliente conecta-sa na porta TCP 4460 do servidor. Cliente e servidor executam um handshake TLs e negociam alguns parâmetros de segurança extras. O Servidor envia então ao cliente alguns cookies que serão usados na posterior troca de mensagens via protocolo NTP, envia também o IP e porta do servidor NTP para o qual os cookies são válidos. Nessa altura a fase NTS-KE do protocolo termina. Idealmente o cliente nunca mais precisa se conectar no servidor NTS-KE e pode seguir trocando pacotes NTP. Contudo em alguns casos esse processo pode ser repetido.
Após terminada a fase NTS-KE se inicia a efetiva sincronização com NTP e NTS. O cliente envia ao servidor um pacote NTP com vários campos de extensão, entre eles um cookie dos que recebeu do servidor NTS-KE e uma tag de autenticação. O servidor usa o cookie para recuperar a chave criptográfica e envia uma resposta autenticada. A resposta inclui um cookie, criptografado. Na próxima requisição o cliente enviará esse cookie, mas sem criptografia. Essa constante renovação dos cookies garante a privacidade.
Chrony e NTPSec implementam o NTS, tanto na função servidor, como cliente.
O uso do NTS é recomendado sempre que possível. Em particular para servidores o uso de NTS é bastante importante. Caso o sistema operacional ainda não tenha um cliente com suporte a NTS, por exemplo no caso de servidores Windows, ou equipamentos de rede, é recomendável que este equipamento seja cliente de servidores NTP na rede local, estes por sua vez funcionando como clientes do NTP.br, utilizando NTS.
(1) Uma importante referência para esta página, inclusive a partir da qual algumas figuras foram adaptadas, foi: TORRES JÚNIOR, PEDRO R. Caracterização da Rede de Sincronização na Internet. Dissertação de Mestrado. 2007. Universidade Federal do Paraná. Curitiba.

